
If you built an AI tool, which model should you choose? The answer is not always easy. Today, many people talk about N Gram vs RNN vs LLM, but few explain what truly fits your goal. With rising data costs and real-time apps everywhere, knowing the right choice can save both money and time.
In this guide, we will show when each model works best. You will learn the strengths, limits, and tradeoffs of every type. We will explore real examples, simple tools, and tests that show how each model behaves in real life. By the end, you will know how to pick what fits your data, speed, and budget.
What Are N-gram, RNN, and LLM?
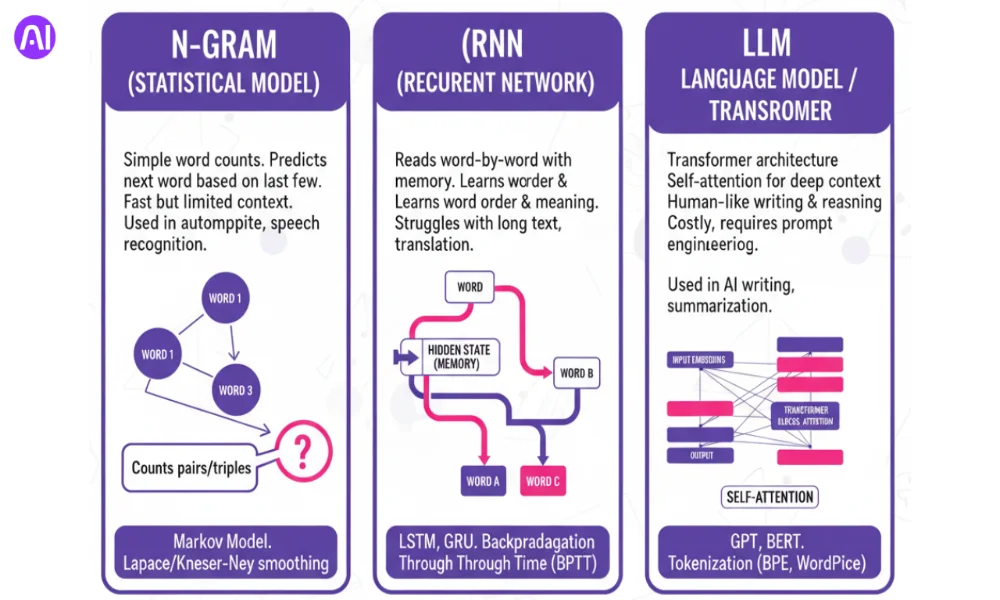
N-gram, RNN, and LLM are three ways to help computers understand language. N-gram uses simple word counts. RNN adds memory to learn from word order. LLMs use transformers that read long text and find deep meaning. Each model works best for different needs, from small chat apps to smart AI tools that can write and reason like humans.
2.1 What is an N-gram (statistical) model?
An N-gram model predicts the next word by looking at the last few words in a sentence. It is a simple statistical language model that counts how often words appear together. It works fast, but it struggles with long or new word patterns. Still, it powers tools like autocomplete and speech recognition.
The Basics of N-gram Models
An N-gram model is the most basic type of language model. It uses word counts to guess what comes next in a sentence. For example, if you type “I am,” the model looks at word pairs, called bigrams, and may predict “happy” or “tired.” A trigram uses three words, like “I am very.”
How N-gram Models Work?
N-gram models are based on the Markov model, which means they depend only on a few recent words, not the whole sentence. This makes them easy to build and very fast. But they have limits. They cannot handle long context, and they fail when a word combo has never been seen before. To fix this, methods like Laplace or Kneser-Ney smoothing fill in missing data.
Where N-gram Still Wins
Still, their perplexity scores are higher than newer models, meaning they are less accurate. Yet, for small tasks, N-grams remain useful because they are simple, count-based, and quick to run.
2.2 What is an RNN (recurrent neural network) in language modeling?
An RNN reads text one word at a time and remembers what came before. It is smarter than N-grams because it uses a memory cell to learn order and meaning. It powers chatbots, speech apps, and translation tools. Still, it struggles when the text is long because its memory fades over time.
Understanding How RNNs Work
A Recurrent Neural Network (RNN) is a neural model that handles sequences, like sentences or speech. It passes information from one step to the next, so it “remembers” what came before. This makes it better at understanding context than simple word counts.
How RNNs Learn
RNNs have a hidden state that keeps memory. During training, they learn by a process called backpropagation through time (BPTT). But basic RNNs face problems with vanishing or exploding gradients, which make it hard to learn from long sentences.
Modern Variants of RNNs
To solve this, improved types like LSTM (Long Short-Term Memory) and GRU (Gated Recurrent Unit) were made. These handle longer context and store key information for many steps. RNNs are great for sequence modeling tasks like captioning, text prediction, and voice-to-text conversion. They balance power and speed better than N-grams but are lighter than huge LLMs.
2.3 What is a LLM (Large Language Model / Transformer-based)?
A Large Language Model (LLM) is built on transformers that use attention to understand meaning across long text. It can write, summarize, and reason with human-like skill. LLMs learn from billions of words, making them powerful but costly to run. They work best for complex tasks and flexible NLP pipelines.
How LLMs Understand Language
A Large Language Model uses a transformer architecture to handle long text with deep context. It replaces the step-by-step reading of RNNs with self-attention, a method that lets the model see all words at once. This helps it learn meaning and relationships between distant words.
Why Size Matters in LLMs
The “large” in LLM comes from massive training data and billions of parameters. This size gives it strong semantic understanding, but also makes it expensive in compute cost and inference latency.
Strengths and Weaknesses of LLMs
LLMs like GPT and BERT outperform older models on tasks like translation, summarization, and coding. They rely on tokenization methods like BPE or WordPiece to break text into pieces for training.
However, they are not perfect. They require huge memory and power. They also depend on careful prompt engineering to get good results. Still, for most modern language model tasks, LLMs lead the field in both accuracy and generalization.
Side-by-Side Comparison: Strengths & Weaknesses

Each model, N-gram, RNN, and LLM has its own strengths and limits. N-grams are simple and fast. RNNs balance memory and accuracy. LLMs handle long text with deep meaning but need more power. This section shows a full comparison with real pros, cons, and ideal use cases. You will see when each model shines and how hybrid setups can boost results.
3.1 Comparison Table: N Gram vs RNN vs LLM
This table highlights how N Gram vs RNN vs LLM differ in strengths, costs, and best uses.
| Model | Pros | Cons | Ideal Use Cases | Resource Needs |
| N-gram (Statistical) | Simple to build, very fast, low memory use | Weak for long context, sparse data, limited vocabulary | Autocomplete, text search, speech tagging | Low CPU, minimal RAM |
| RNN (Neural) | Learns order and meaning, handles medium-length text | Struggles with long memory, slower than N-gram | Chatbots, speech-to-text, captioning | Moderate GPU, average training time |
| LLM (Transformer-based) | Best for context, writing, and reasoning, understands deep meaning | High cost, slow inference, large memory use | Content creation, translation, question answering | High-end GPUs, strong compute setup |
| Hybrid Models (RNN + N-gram / Smoothed) | Combines speed and accuracy, reduces errors on rare words | Harder to tune, needs integration | Mobile prediction, real-time typing tools | Medium compute, optimized setup |
3.2 Detailed Tradeoffs & When Each Shines
N-gram: Simple and Fast for Short Tasks
The N-gram model shines when you need quick and light predictions. It works best with short sequences and fixed vocabularies, like in search boxes or text autocomplete. It uses fast lookup tables and gives results instantly. But since it only looks at a few words, it cannot catch deeper meanings or long dependencies in text.
RNN: Smart Memory for Medium Sequences
The Recurrent Neural Network bridges the gap between N-grams and LLMs. It remembers word order and captures flow in text. RNNs, especially LSTM and GRU, learn well on medium data sizes without needing huge GPUs. They work best for tasks like captioning or real-time translation. Yet, they can struggle with very long text because of vanishing gradients and slower inference speed.
LLM: Deep Understanding with High Cost
Large Language Models stand at the top for text comprehension and generation. They use attention mechanisms to handle long context and create coherent responses. LLMs excel in zero-shot or few-shot learning, where they perform well without task-specific training. But this power has a price: high compute cost, large memory, and slower responses. For real-time systems, that can mean higher latency.
3.3 Edge Cases & Interpolations
Blending RNN and N-gram Models
In some systems, a blend of RNN and N-gram smoothing is used. This hybrid method improves prediction on rare or unseen words. For example, Google once tested LSTM smoothing to boost language prediction accuracy in mobile keyboards while keeping speed high.
Lightweight and Distilled LLMs
To make LLMs usable on smaller devices, developers use model distillation, pruning, and quantization. These reduce model size and memory use while keeping accuracy close to full-scale transformers. Such compact versions power on-device assistants and offline chat tools.
Layered and Ensemble Systems
Many production apps use layered models. They start with N-grams for speed, switch to RNNs for better context, and fall back to LLMs for complex or rare queries. These ensemble models combine the best of all worlds: fast lookup, smart memory, and deep understanding. This setup ensures high throughput with controlled latency and resource balance.
How to Choose for Your Scenario (Decision Guide)
4.1 Key Questions to Ask Yourself
The choice between N Gram vs RNN vs LLM depends on your data size, task type, and compute power. Before you pick between N-gram, RNN, or LLM, ask a few simple questions. How big is your dataset, and how much computer power or memory can you use? Do you need answers instantly, like in a chatbot or autocomplete system? How long are your text inputs, and does your task require deep understanding or just pattern matching?
These questions help you match the right model to your goals, whether it’s a fast lookup tool or a smart, context-aware assistant.
4.2 Decision Flow
If your data is small and focused on a specific area, an N-gram model works best. It’s quick and light. If you have medium-sized data and deal with ordered sequences, use an RNN, as it remembers patterns in order.
But if your work covers many topics and you want a model that understands meaning and context deeply, go for an LLM. For balanced performance, you can even mix them like using RNNs with N-gram backups for rare words.
4.3 Example Scenarios & Picks
For a chatbot trained on company knowledge, an RNN or small LLM is a smart pick for accuracy and context. Meanwhile, mobile autocomplete benefits from N-gram models due to their fast inference and lightweight design.
For creative writing, summarization, or translation, use an LLM, since it handles complex text and can adapt to many topics. These examples show how domain adaptation, transfer learning, and zero-shot learning shape the right choice for each task.
Tools, Libraries & Frameworks to Experiment With
NLTK
NLTK (Natural Language Toolkit) is great for beginners who want to explore how N-gram models and simple NLP pipelines work. It includes tools for tokenization, stemming, and generating N-grams. It’s easy to learn but not meant for large-scale or production systems. Use it for education, small experiments, and basic text analysis.
Keras, TensorFlow & PyTorch
These deep learning frameworks let you design and train your own RNN, LSTM, or Transformer models. Keras is simple and beginner-friendly, while TensorFlow and PyTorch give more control for advanced users. They are best suited for research and custom model development but require more compute power.
Hugging Face Transformers
Hugging Face Transformers offers ready-to-use models like BERT, GPT, and T5. You can fine-tune them for your tasks with minimal setup. It’s ideal when you want LLM-level performance without training from scratch. Perfect for developers focusing on accuracy and scalability.
OpenAI API / GPT Endpoints
If you want to use powerful LLMs like GPT models instantly, the OpenAI API is the fastest option. It skips training and setup, giving access through simple API calls. Great for production, prototypes, or commercial apps that need human-like text generation with minimal infrastructure.
ONNX, TensorRT & Quantization Tools
When models need to run on limited hardware or in real-time systems, tools like ONNX, TensorRT, and quantization libraries help optimize performance. They reduce model size and speed up inference, making them ideal for mobile or edge devices.
spaCy & AllenNLP
spaCy and AllenNLP provide complete NLP workflows with built-in tokenization, embeddings, and named entity recognition. They’re perfect for building production-ready text pipelines that balance speed, accuracy, and usability. Use them when you need structured NLP systems rather than end-to-end text generation.
Performance Metrics: How to Evaluate
To judge models like N-gram, RNN, and LLM, experts look at metrics such as perplexity, accuracy, latency, and memory size. Lower perplexity means better predictions, while higher accuracy or BLEU/ROUGE scores mean stronger understanding. Real-world tests also check speed and user satisfaction to decide which model truly fits your task.
Perplexity and Cross-Entropy
Perplexity tells how well a model predicts the next word in a sequence. It’s based on cross-entropy loss, lower values mean smarter predictions. Traditional N-gram models often show higher perplexity (150–200 on WikiText), while RNNs drop this to around 120. Transformers and LLMs can go even lower, often below 50 on the same datasets, proving their superior context handling.
Accuracy, BLEU, ROUGE, and WER
When testing how well models handle tasks like translation or summarization, researchers use BLEU, ROUGE, and WER scores. RNNs improved BLEU scores over N-grams by 10–20% on average, but LLMs now outperform them by wide margins due to better context and meaning tracking.
Latency and Throughput
Latency is how long a model takes to produce a result, and throughput is how many tokens it processes per second. N-grams are lightning fast because they only look up stored counts. RNNs are slower since they process one step at a time. LLMs, though accurate, need heavy compute and have higher latency, fine-tuning or quantization helps balance speed and quality.
Memory Footprint and Model Size
N-grams use small memory but struggle with big vocabularies. RNNs are compact yet need GPUs for training. LLMs can have billions of parameters, sometimes exceeding 10 GB+ memory, so they require powerful hardware or APIs. Optimization methods like pruning and distillation help reduce size without losing much accuracy.
Real User Metrics
Beyond benchmarks, models must perform well in real use. Metrics like engagement rate, completion success, and error rate reveal how useful they are for users. A chatbot that answers faster but less accurately may still fail in practice. This is why LLMs, despite their cost, often deliver better user satisfaction and task success in real-world NLP pipelines.
Common Pitfalls & Myths (What You Should Watch Out For)
Many developers test N Gram vs RNN vs LLM to see which model gives better accuracy without raising cost. Many believe LLMs are always the best, but that is not true. Choosing the wrong model can waste time, money, and compute. You must match the tool to your data size, task, and system speed. Be careful of bias, overfitting, and hallucinations. Always test models in real settings and keep a human in the loop for quality control.
Myth 1: “LLMs Are Always Better”
This is one of the biggest misunderstandings. Large Language Models like GPT or BERT perform great on many tasks but can be too heavy for smaller jobs. For short texts or fixed domains, N-gram or RNN models can give faster and cheaper results. Always check if you really need LLM-level power before using it.
Overfitting on Small Data
When you use a huge model on a small dataset, it often memorizes patterns instead of learning. This is called overfitting. It looks good in training but fails on new text. To avoid this, use regularization, data augmentation, or smaller models that fit your data scale.
Ignoring Real-Time and Resource Limits
Many projects fail because teams forget about latency and memory. A model that gives great accuracy but takes 5 seconds to answer can’t run in chat or voice apps. Before deployment, test throughput and inference speed under real workloads.
Misleading Metrics and Hidden Costs
Metrics like perplexity may look good but don’t always reflect real-world usefulness. A low perplexity model might still give dull or biased answers. Always combine quantitative scores with user testing to judge actual quality.
Bias, Hallucination, and Reproducibility Issues
LLMs sometimes generate false or biased content, known as hallucination. They can also behave differently each time due to stochastic sampling. To reduce these risks, use domain filtering, prompt tuning, and human review. Also, document settings to improve reproducibility.
Smart Tip: Use Hybrid or Fallback Systems
Many experts mix models for better results. For example, using N-gram or RNN as a fallback when LLM confidence is low helps control cost and errors. Keeping a human reviewer for sensitive outputs also makes your system more trustworthy and stable.
Case Study 1: ASR with Lattice Rescoring Using LSTM / RNN LM vs N-gram
User: Researchers building a speech recognition system (e.g. from Google / YouTube) to improve transcription accuracy.
Challenge: The base system used an N-gram language model for decoding, but had too many wrong words (high WER, Word Error Rate), especially in long utterances. They needed better accuracy without huge slowdown.
Solution: They added lattice rescoring with an LSTM or RNN language model after the N-gram pass. The N-gram LM first produces many candidate transcriptions (a lattice). Then the RNN/LSTM model rescores those candidates to pick the best one. This lowered the WER.
Takeaway: Hybrid (N-gram + RNN) gives much better accuracy than N-gram alone. It adds cost (compute for rescoring) but keeps latency reasonable. Good when you need good quality but can afford a second pass.
Case Study 2: Medical Chatbot Using RAG + Mistral-7B (LLM)
User: An AI enthusiast / developer who built a medical chatbot to give treatment guidelines.
Challenge: Regular LLMs sometimes hallucinate (make up info) or give generic answers. Medical domain needs precision. Also, having a large labeled dataset was hard. They needed something more accurate and safe.
Solution: They used a lightweight LLM (Mistral-7B) combined with a Retrieval‐Augmented Generation (RAG) pipeline. They fetched relevant documents (medical PDFs) and used the LLM to generate answers grounded in that content. This reduced hallucination. The system did not need huge labeled data.
Takeaway: For domain specific tasks and limited data, using LLM + external retrieval gives better accuracy and generalization. The cost is higher than simple models, but it brings much more safety and trust.
Conclusion
N-gram models are fast, light, and easy to use. They work well when your domain is small and your text is short. RNNs (with LSTM or GRU) bring memory. They do better than N-grams for medium-length text and ordered sequences. LLMs (transformer models) work best when you need deep understanding, creative output, or long context across many topics.
For small, narrow datasets, an N-gram model works best. When you have moderate data and need a balance of speed and context, RNNs are ideal. For broad domains like summarization, question answering, or creative writing, LLMs or hybrid solutions perform the best.
Now you know where each shines in the N Gram vs RNN vs LLM debate, pick smart and test your case.
Stay updated on AI trends! For more expert tips and the latest breakthroughs, follow AI Ashes Blog. Dive deeper into machine learning, data science, and cutting-edge AI research.
Check out this article on Master NLP Best Practices for Analyzable & Clear Data.
FAQs
1. What is the difference between N Gram vs RNN vs LLM?
An N-gram is a count-based model that looks at recent words. An RNN is a neural model that has memory of word order. An LLM (large language model) uses transformer and attention to understand long context. Each is statistical vs neural vs transformer style language model.
2. Can an N-gram model beat an RNN or LLM?
Yes, in small domains with limited vocabulary and tight latency needs, N-gram can win. It is fast, cheap, and simple. But for broader tasks or long text, RNN or LLM often outperform.
3. Why use RNN over LLM for some tasks?
RNNs are lighter, use less compute, and have lower inference latency in many cases. For tasks with medium sequence length and limited GPU, RNN may be the sweet spot.
4. When do I need an LLM instead of RNN?
Use an LLM when your task must understand deep context, generate long passages, or generalize across many domains. If you need semantic understanding and flexibility, LLMs shine.
5. What is latency, throughput, and inference speed?
Latency is how fast the model responds. Throughput is how many tokens it processes per second. Inference speed is how quick the model makes predictions. These metrics matter a lot in real-time apps.
6. Can I mix N-gram with RNN or LLM?
Yes, many systems use hybrid models. For rare words, they fall back to N-gram. For common or complex queries, they use RNN or LLM. The mix improves accuracy and reduces cost.
7. Does using an LLM always cost more?
Usually yes. LLMs need more compute, memory, and power. They also have higher deployment cost and often more latency. So they are best when high quality and breadth are critical.
8. How do I evaluate these models?
Use metrics like perplexity, BLEU, ROUGE, or WER. Also measure real metrics: error rate, user satisfaction, and speed constraints in your app.
9. What is overfitting and domain shift?
Overfitting means the model learns your training data too well and fails on new data. Domain shift is when real usage differs from training data domain. Both problems hurt model reliability.
10. Why do LLMs hallucinate or show bias?
Because they generate text based on patterns in data, they can invent wrong facts (hallucination) or reflect data bias (bias). Mitigation needs prompt tuning, oversight, or fallback checks.






